
La computación acelerada, con su poder de procesamiento sin precedentes, ha asumido un papel central en la infraestructura de la nube, ya que ayuda a gestionar grandes cantidades de información en los centros de datos de manera más eficiente y efectiva. Además, la computación acelerada proporciona la potencia computacional y la memoria necesarias para entrenar e implementar modelos avanzados de IA generativa, como GPT-4, de manera más eficiente. Esta capacidad permite tiempos de entrenamiento más rápidos, el manejo de grandes conjuntos de datos y el desarrollo de modelos cada vez más complejos.
La computación acelerada utiliza hardware especializado como GPU, ASIC, TPU y FPGA para ejecutar cálculos de manera más eficiente que las CPU, lo que mejora la velocidad y el rendimiento. Es especialmente beneficioso para tareas que se pueden paralelizar, como en informática de alto rendimiento, aprendizaje profundo, aprendizaje automático e inteligencia artificial.
El mundo de la computación acelerada es vasto y está en constante evolución, repleto de diversas soluciones de hardware y software como GPU, ASIC, TPU, FPGA, CUDA, OpenCL y diversas tecnologías de red. Centro Infra profundiza en las implementaciones prácticas de estas soluciones en la nube con grandes proveedores como Amazon Web Services (AWS), Google Cloud y Microsoft Azure. También exploramos su impacto en las aplicaciones impulsadas por IA, incluida la IA generativa y los centros de datos. Continúe leyendo para comprender las enormes implicaciones que la computación acelerada puede tener en la remodelación de nuestro futuro tecnológico.
¿Qué es la Computación Acelerada?
La computación acelerada se refiere al uso de hardware especializado para realizar ciertos tipos de cálculos de manera más eficiente de lo que es posible con unidades centrales de procesamiento (CPU) de propósito general únicamente. Este concepto aprovecha el poder de dispositivos como unidades de procesamiento de gráficos (GPU), circuitos integrados de aplicaciones específicas (ASIC), incluidas unidades de procesamiento de tensores (TPU), y matrices de puertas programables en campo (FPGA) para realizar cálculos a velocidades significativamente más altas, acelerando así el proceso.
Estos aceleradores son particularmente adecuados para tareas que pueden dividirse en tareas paralelas más pequeñas, como las que a menudo se encuentran en la computación de alto rendimiento (HPC), el aprendizaje profundo, el aprendizaje automático (ML), la inteligencia artificial (IA) y el análisis de big data. Al descargar ciertos tipos de cargas de trabajo a estos dispositivos de hardware especializados, la computación acelerada mejora enormemente el rendimiento y la eficiencia de estos sistemas.
Importancia de la computación acelerada
El fin de la Ley de Moore, que postula que la potencia informática aproximadamente se duplica cada dos años a un costo constante, ha marcado una desaceleración en el crecimiento del rendimiento de la CPU. Esto ha provocado un cambio hacia la computación acelerada y ha planteado dudas sobre la viabilidad a largo plazo del actual mercado de un billón de dólares para servidores sólo con CPU. Con la creciente demanda de aplicaciones y sistemas más potentes, los métodos de CPU tradicionales luchan por competir con la computación acelerada, que ofrece actualizaciones de rendimiento más rápidas y rentables.
La computación acelerada es vital debido a su capacidad para procesar volúmenes masivos de datos de manera eficiente, impulsando así avances en aprendizaje automático, inteligencia artificial, análisis en tiempo real e investigación científica. Su creciente influencia en los gráficos, los juegos, la informática de punta y la computación en la nube forman la columna vertebral de la infraestructura digital, como los centros de datos, necesarios para nuestro mundo cada vez más interconectado y basado en datos.
Soluciones de computación acelerada: hardware, software y redes
Las soluciones de computación acelerada implican una combinación de hardware, software y redes. Estas soluciones están diseñadas específicamente para mejorar la velocidad y la eficiencia de tareas computacionales complejas, principalmente realizándolas en paralelo.
Aceleradores de hardware
Los aceleradores de hardware son fundamentales para la computación acelerada y superan significativamente lo que las unidades centrales de procesamiento (CPU) tradicionales pueden lograr por sí solas. Estos aceleradores incluyen unidades de procesamiento de gráficos (GPU), circuitos integrados de aplicaciones específicas (ASIC) y conjuntos de puertas programables en campo (FPGA).
| — | GPUs | ASIC | FPGA |
| Propósito | Computación de propósito general | Sólo tareas específicas; totalmente personalizado | Programable para varias tareas. |
| Velocidad | Alta | Más alta | Más baja que las GPU y ASIC |
| Flexibilidad | Baja | Mínima (tarea única) | Alta (totalmente reconfigurable) |
| Costo | >$10,000 | $5,000 o menos; depende del volumen | $3,000 a $10,000 |
| Tiempo de desarrollo | Bajo | Más alto (requiere diseño personalizado) | Moderado (requiere programación) |
| Eficiencia energética | Moderada | Más alta | Moderada a alta |
| Software y APIs | CUDA, OpenCL | Personalizado para procesadores individuales | Verilog, VHDL, OpenCL, HLS |
| Casos de uso típicos | Juegos, IA/ML, gráficos | Minería de criptomonedas, cálculos específicos | Creación de prototipos y cálculos adaptables. |
Unidades de procesamiento de gráficos (GPU)
Las unidades de procesamiento de gráficos (GPU) son procesadores especializados que se utilizan ampliamente para una variedad de tareas computacionales intensivas. Son especialmente competentes para realizar muchos cálculos complejos simultáneamente, lo que los hace muy adecuados para tareas como la computación de alto rendimiento (HPC) y el entrenamiento de redes neuronales en el aprendizaje automático.
En el contexto de la aplicación, el término unidad de procesamiento de gráficos de propósito general (GPGPU) se utiliza a menudo para describir el uso de una GPU para cálculos que tradicionalmente maneja la unidad central de procesamiento (CPU), en campos más allá de la representación de gráficos.
NVIDIA lidera el mercado de GPU utilizadas para centros de datos y tareas informáticas intensivas, como el aprendizaje automático y la inteligencia artificial. Las principales arquitecturas de GPU de la empresa para centros de datos incluyen Hopper (H100) y Ampere (A100). En particular, las GPU H100 son adecuadas para acelerar aplicaciones que involucran modelos de lenguaje grandes (LLM), sistemas de recomendación profundos, genómica y gemelos digitales complejos.
Circuitos integrados de aplicaciones específicas (ASIC)
Los circuitos integrados de aplicaciones específicas (ASIC) son chips personalizados diseñados para realizar una tarea específica, a diferencia de las CPU de uso general que están diseñadas para manejar una amplia variedad de aplicaciones. Dado que los ASIC están diseñados a la medida para una función particular, ejecutan esa tarea de manera más eficiente que un procesador de propósito general. Esto se traduce en ventajas en términos de velocidad, consumo de energía y rendimiento general.
Unidad de procesamiento neuronal (NPU) y procesador de aprendizaje profundo (DLP) son términos que se utilizan a menudo para referirse a tipos específicos de ASIC, que están diseñados para acelerar las cargas de trabajo de IA. Un ejemplo destacado de un ASIC en el contexto de la computación acelerada es la unidad de procesamiento tensorial (TPU) de Google. Los TPU están diseñados específicamente para acelerar las cargas de trabajo de aprendizaje automático. Se utilizan ampliamente en los centros de datos de Google para tareas como traducción de idiomas, reconocimiento de voz en el Asistente de Google y cargas de trabajo de clasificación de publicidad programática.
Matrices de puertas programables en campo (FPGA)
Los conjuntos de puertas programables en campo (FPGA) son circuitos integrados de semiconductores que se pueden reprogramar para realizar tareas específicas de manera más eficiente que las CPU de uso general. A diferencia de las arquitecturas fijas que se encuentran en ASIC, GPU y CPU, el hardware FPGA incluye bloques lógicos configurables e interconexiones programables. Esto permite actualizaciones de funcionalidad incluso después de que el chip haya sido enviado e implementado.
Los FPGA son cada vez más populares en los centros de datos para la computación de alto rendimiento (HPC) y la aceleración AI/ML, dada su flexibilidad y capacidades de computación paralela. Sin embargo, son más lentas que las GPU y las soluciones ASIC personalizadas, y su ecosistema de software no está tan desarrollado. La lenta adopción de FPGA para cargas de trabajo de IA se debe principalmente a su complejidad de programación, lo que ha resultado en un número limitado de ingenieros especializados.
Software y API
La informática acelerada utiliza interfaces de programación de aplicaciones (API) y modelos de programación como CUDA y OpenCL para interactuar con aceleradores de software y hardware. Esto optimiza el flujo de datos para lograr un mejor rendimiento, eficiencia energética, rentabilidad y precisión. Las API y los modelos de programación permiten a los desarrolladores escribir código que se ejecuta en GPU y utilizar bibliotecas de software para una implementación eficiente de algoritmos.
CUDA (Arquitectura de dispositivo unificado de computación)
CUDA (Compute Unified Device Architecture) es una plataforma informática paralela propietaria y un modelo de interfaz de programación de aplicaciones (API) desarrollado por NVIDIA. Permite el uso de GPU NVIDIA para procesamiento de propósito general, lo que resulta en una aceleración significativa de las tareas computacionales. La plataforma incluye bibliotecas de aprendizaje profundo como cuDNN, TensorRT y DeepStream para mejorar las tareas de inferencia y entrenamiento de IA.
Desde su introducción en 2006, CUDA se ha descargado 40 millones de veces y cuenta con una base de usuarios de 4 millones de desarrolladores en todo el mundo. Esta amplia adopción proporciona nuevas aplicaciones desarrolladas utilizando la plataforma CUDA con una importante comunidad de desarrolladores. Como CUDA es una plataforma patentada con una amplia base de desarrolladores, NVIDIA tiene una ventaja significativa en el mercado de hardware y software de centros de datos. En consecuencia, los proveedores más pequeños a menudo se encuentran en desventaja, ya que deben confiar en la plataforma OpenCL, que no ofrece un rendimiento a la par de CUDA.
OpenCL (lenguaje informático abierto)
OpenCL (Open Computing Language) es una plataforma de código abierto diseñada para computación paralela. Admite una amplia gama de hardware informático, incluidos CPU, GPU, FPGA y otros tipos de procesadores. Esta amplia compatibilidad permite a los desarrolladores aprovechar el poder de estos diversos componentes de hardware, acelerando las tareas informáticas. Una característica particularmente notable de OpenCL es su portabilidad entre diferentes tipos de hardware.
Redes
Las redes desempeñan un papel crucial en la computación acelerada, ya que facilitan la comunicación entre decenas de miles de unidades de procesamiento, como GPU, así como dispositivos de memoria y almacenamiento. Se utilizan varias tecnologías de red para permitir la comunicación entre estos dispositivos informáticos y el resto del sistema, y para compartir datos entre múltiples dispositivos dentro de una red. Estos incluyen:
- PCI Express (PCIe): este estándar de bus de expansión de computadora en serie de alta velocidad proporciona una conexión directa entre los dispositivos informáticos y la CPU/memoria. En la informática acelerada, PCIe se utiliza habitualmente para conectar GPU u otros aceleradores al sistema principal.
- NVLink: La tecnología de interconexión de alto ancho de banda y eficiencia energética patentada de NVIDIA proporciona un ancho de banda significativamente mayor que PCIe. Está diseñado para facilitar un intercambio de datos más eficiente entre GPU y también entre GPU y CPU.
- Infinity Fabric: La tecnología de interconexión patentada de AMD se utiliza para conectar varios componentes dentro de sus chips, incluidas CPU, GPU y memoria.
- Compute Express Link (CXL): un estándar de interconexión abierto, CXL ayuda a reducir la latencia y aumentar el ancho de banda entre las CPU y los aceleradores. Consolida múltiples interfaces en una conexión PCIe al procesador host
- InfiniBand: una tecnología de interconexión de alta velocidad y baja latencia que se utiliza a menudo en configuraciones de informática de alto rendimiento (HPC). Permite la interconexión de alta velocidad entre grupos de servidores y dispositivos de almacenamiento.
- Ethernet: esta tecnología de red generalizada, rentable y flexible se utiliza para transferir grandes cantidades de datos entre servidores en un centro de datos, lo cual es crucial para muchas tareas informáticas aceleradas. Sin embargo, no proporciona el mismo nivel de rendimiento que NVLink o InfiniBand
GPU conectadas a una CPU mediante NVLink y PCIe
El siguiente es un diagrama que ilustra la arquitectura de las GPU conectadas a una CPU mediante métodos de conectividad NVLink y PCIe.
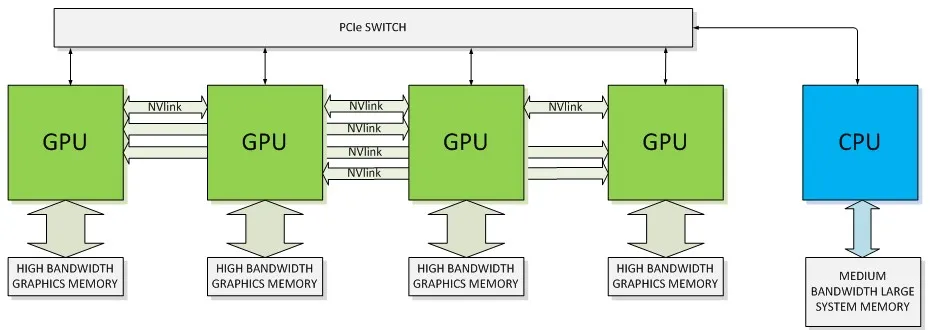
Fuente: NVIDIA.
Instancias de Computación Acelerada en la Nube
En el contexto de la computación en la nube, las instancias de computación acelerada se refieren a instancias de máquinas virtuales (VM) que utilizan aceleradores de hardware o coprocesadores para realizar tareas como cálculos de números de punto flotante, procesamiento de gráficos y coincidencia de patrones de datos de manera más eficiente que lo que se puede lograr solo con software ejecutado por CPU.
Estas instancias de computación acelerada vienen equipadas con varios tipos de aceleradores de hardware, como unidades de procesamiento de gráficos (GPU), circuitos integrados de aplicaciones específicas (ASIC) o conjuntos de puertas programables en campo (FPGA), que se alojan en centros de datos en la nube.
Los proveedores de servicios en la nube (CSP), como Amazon Web Services (AWS), Google Cloud Platform (GCP) y Microsoft Azure, ofrecen una variedad de instancias informáticas aceleradas diseñadas para manejar diferentes tipos de cargas de trabajo. Además, una nueva generación de empresas de GPU como servicio (GPUaaS), incluidas CoreWeave, Lambda Labs, Denvr Dataworks, Applied Digital y Crusoe, están surgiendo para cumplir esta función.
La principal ventaja de utilizar estas instancias de computación acelerada basadas en la nube es que los usuarios finales pueden acceder a potentes capacidades informáticas aceleradas por hardware bajo demanda, operando en forma de pago por uso, eliminando la necesidad de grandes inversiones de capital iniciales en hardware.
Servicios web de Amazon (AWS)
Amazon Web Services (AWS), a través de Amazon Elastic Compute Cloud (EC2), proporciona instancias GPU, como los tipos de instancia P3, P4, G3, G4 y G5. Estas instancias utilizan GPU NVIDIA y son adecuadas para el aprendizaje automático (por ejemplo, entrenamiento de nuevos modelos), informática de alto rendimiento (HPC) y aplicaciones con uso intensivo de gráficos. AWS, a través de Amazon EC2, también ofrece instancias F1 que utilizan FPGA para permitir la entrega de aceleraciones de hardware personalizadas para cargas de trabajo como genómica, búsqueda/análisis, procesamiento de imágenes y videos, seguridad de red y análisis de big data.
Además, AWS, a través de Amazon EC2, ofrece sus propios aceleradores ASIC personalizados, conocidos como AWS Inferentia y AWS Trainium, que están diseñados para cargas de trabajo de aprendizaje automático, específicamente inferencia y capacitación, respectivamente.
- AWS Inferentia (Inf1): ofrece el costo de inferencia más bajo en la nube para ejecutar modelos de aprendizaje profundo, proporcionando hasta un 70 % menos de costo por inferencia que instancias de GPU comparables.
- AWS Trainium (Trn1): la instancia de capacitación de aprendizaje profundo de alto rendimiento más rentable en la nube, que ofrece hasta un 50 % de ahorro en el costo de capacitación en comparación con instancias de GPU comparables.
Si bien los aceleradores ASIC personalizados de AWS no pueden reemplazar la funcionalidad avanzada de las GPU NVIDIA de última generación, tienen el potencial de ofrecer niveles de rendimiento comparables a ciertos modelos de GPU NVIDIA, pero a un costo reducido.
Nube de Google
Las instancias Cloud TPU de Google brindan acceso a unidades de procesamiento tensorial (TPU), un tipo particular de circuito integrado específico de aplicación (ASIC), para cargas de trabajo de aprendizaje automático. La última unidad de procesamiento de tensores desarrollada a medida por la empresa se conoce como TPU v4.
TPU v4 de Google Cloud ofrece rendimiento de aprendizaje automático (ML) a exaescala, con un aumento de 10 veces en el rendimiento del sistema ML con respecto a su predecesor, el TPU v3. Este desarrollo mejora significativamente la eficiencia energética, aproximadamente 2 a 3 veces más en comparación con los aceleradores específicos de dominio (DSA) de ML contemporáneos, al tiempo que reduce las emisiones de dióxido de carbono equivalente (CO2e) aproximadamente 20 veces.
Google ejecuta más del 90% de su entrenamiento interno de IA en sus TPU personalizados, y el 10% restante se ejecuta en silicio comercial como las GPU NVIDIA. A medida que aumentan las cargas de trabajo de los transformadores, representan una proporción mayor de la combinación de capacitación de Google. Por ejemplo, los LLM que se ejecutan en TPU ya constituyen más del 30% de las necesidades de formación de Google. En particular, el 100% de las cargas de trabajo de inferencia de Google se ejecutan en TPU.
En una oferta separada, Google Cloud proporciona instancias optimizadas para acelerador (A2) que están equipadas con GPU NVIDIA A100. Estas instancias están diseñadas para cargas de trabajo de informática de alto rendimiento (HPC), análisis de datos y aprendizaje automático.
MicrosoftAzure
Microsoft Azure proporciona tamaños de máquinas virtuales (VM) optimizadas para GPU para cargas de trabajo de visualización y computación intensiva, con uso intensivo de gráficos, con varias GPU y CPU de NVIDIA y AMD. Las ofertas de la compañía incluyen las series NCv3 y NC T4_v3 para aplicaciones de computación intensiva, la serie ND A100 v4 para aprendizaje profundo y aplicaciones HPC aceleradas, las series NV y NVv3 para visualización remota, y la serie NVv4 para VDI y visualización remota con GPU particionadas.
Computación acelerada e IA generativa
La computación acelerada es un habilitador fundamental para el desarrollo y la implementación de modelos avanzados de inteligencia artificial (IA) generativa. La IA generativa implica el uso de algoritmos para crear nuevos datos que sean similares en características estadísticas al conjunto de entrenamiento, con ejemplos notables en los dominios de imágenes, texto y voz.
En el campo de la IA generativa, se utilizan modelos como Generative Adversarial Networks (GAN), Variational Autoencoders (VAE) y Transformers, que incluyen grandes modelos de lenguaje (LLM) de ChatGPT de OpenAI. Implican operaciones matemáticas complejas, entrenamiento en grandes conjuntos de datos y requieren una gran cantidad de memoria y potencia computacional. Más específicamente, el tamaño del modelo, la complejidad por capa, la longitud de la secuencia y la diversificación son factores que aumentan las necesidades computacionales.
La computación acelerada desempeña un papel particularmente importante a la hora de abordar los requisitos de memoria y potencia computacional de la IA generativa. Sus capacidades pueden acelerar los tiempos de entrenamiento, manejar grandes conjuntos de datos, habilitar modelos complejos, facilitar generaciones en tiempo real y garantizar cálculos de gradientes eficientes.
1. Acelerar los tiempos de entrenamiento
El papel más importante que desempeña la computación acelerada en la IA generativa es reducir el tiempo que lleva entrenar modelos GAN, VAE y Transformer. Estos modelos suelen tardar días, semanas o incluso meses en entrenarse en arquitecturas tradicionales basadas en CPU.
Las plataformas informáticas aceleradas, como las unidades de procesamiento de gráficos (GPU) y las unidades de procesamiento de tensores (TPU), están diseñadas para procesamiento paralelo. Esto los hace capaces de manejar múltiples cálculos simultáneamente, reduciendo drásticamente los tiempos de entrenamiento.
2. Manejar grandes conjuntos de datos
Los modelos de IA generativa suelen entrenarse en conjuntos de datos masivos. El hardware informático acelerado puede procesar estos conjuntos de datos más grandes de manera mucho más eficiente que las CPU tradicionales. Además, el uso de arquitecturas de memoria avanzadas, como la memoria de alto ancho de banda que se encuentra en algunas GPU, permite el manejo eficiente de estos grandes conjuntos de datos durante el proceso de capacitación.
3. Habilite modelos complejos
El aumento de la potencia computacional que permite la computación acelerada permite la creación de modelos más complejos y más grandes, lo que conduce a mejores resultados. Por ejemplo, los modelos de transformadores más grandes como el GPT-4, que tienen 170 billones de parámetros, sólo son posibles gracias a la computación acelerada.
4. Generaciones en tiempo real
Para determinadas aplicaciones, los modelos de IA necesitan generar resultados en tiempo real (o casi en tiempo real). Esto es particularmente importante para aplicaciones interactivas como la IA en videojuegos y traducciones en tiempo real. La computación acelerada garantiza que estas operaciones se realicen rápidamente, permitiendo así la funcionalidad en tiempo real.
5. Cálculos de gradientes eficientes
Los modelos de aprendizaje profundo aprenden mediante técnicas de optimización basada en gradientes, como la retropropagación. Estos son métodos computacionales que ajustan iterativamente los parámetros de un modelo, en la dirección que minimiza la función de error o pérdida. Estos cálculos se basan en matrices y, por lo tanto, son altamente paralelizables, lo que los hace muy adecuados para soluciones informáticas aceleradas.
Computación acelerada y centros de datos impulsados por IA
El objetivo de las plataformas informáticas aceleradas es acelerar las cargas de trabajo con uso intensivo de computación, incluida la inteligencia artificial, el análisis de datos, los gráficos y la computación científica, en varios tipos de centros de datos. Estos abarcan instalaciones empresariales, de colocación, de hiperescala/nube, de borde y modulares. El objetivo principal es mejorar el rendimiento de la carga de trabajo y al mismo tiempo reducir el consumo de energía y el costo por consulta.
El auge de la IA generativa y los grandes modelos lingüísticos (LLM) entre los consumidores, las empresas de Internet, las empresas y las nuevas empresas ha dado lugar a un momento significativo en la adopción de la IA. Este aumento ha resultado en un aumento considerable en la implementación de inferencias en centros de datos y plataformas en la nube. Actualmente, la mayoría de las cargas de trabajo de inferencia se ejecutan en CPU y tarjetas de interfaz de red (NIC) básicas equipadas con capacidades de procesamiento. Sin embargo, debido al creciente enfoque en el rendimiento, la eficiencia energética, la rentabilidad y las limitaciones de energía, la industria está cambiando hacia la computación acelerada, utilizando hardware especializado como GPU y ASIC.
Una visión para el futuro de los centros de datos modernos implica una “fábrica de IA” en funcionamiento continuo que procese y convierta datos en inteligencia. Estas instalaciones emplearían modelos de IA como LLM, sistemas de recomendación y, eventualmente, modelos de razonamiento. Además, contarán con una flota de inferencia para soportar una variedad de cargas de trabajo, incluido el procesamiento de video, generación de texto, generación de imágenes y gráficos 3D para mundos virtuales y simulaciones.
LEER MÁS: Cómo los centros de datos están permitiendo la inteligencia artificial (IA)
Computación acelerada versus computación optimizada
La elección entre computación acelerada y computación optimizada para computación es relevante al diseñar y administrar centros de datos o seleccionar recursos de computación en la nube. Las tareas que se pueden paralelizar, como el aprendizaje automático, los algoritmos de inteligencia artificial, la representación de gráficos y las simulaciones a gran escala, se benefician más de la computación acelerada. Por el contrario, las tareas que requieren un rendimiento sólido de un solo subproceso, como servir contenido web, bases de datos o ejecutar aplicaciones comerciales, funcionan mejor en sistemas optimizados para computación.
A continuación, comparamos las diferencias clave entre la computación acelerada y la computación optimizada para la computación:
| — | Computación acelerada | Computación optimizada para computación |
| Definición | Utiliza hardware especializado (por ejemplo, GPU) | Utiliza CPU de alto rendimiento |
| Casos de uso | Tareas de aprendizaje automático con uso intensivo de gráficos | Altos cálculos, cargas de trabajo del servidor. |
| Velocidad | Extremadamente rápido con tareas adecuadas (usando procesamiento paralelo) | Rápido pero de propósito general (tareas de un solo subproceso) |
| Costo | Puede resultar caro debido al hardware especializado | Generalmente menos costoso que el acelerado |
| Hardware | Depende de hardware específico, como GPU, TPU o FPGA | Menos dependiente del hardware; utiliza principalmente CPU multinúcleo de alto rendimiento |



