
Las organizaciones están inundadas de datos. Por lo tanto, construyen lagos de datos para aprovechar las enormes cantidades de datos provenientes de una variedad de fuentes. Históricamente, se utilizaba un almacén de datos para almacenar y analizar datos estructurados, pero ahora vivimos en un mundo donde los datos no estructurados y semiestructurados son cada vez más frecuentes. Dada la magnitud de la generación de datos, los proveedores de servicios en la nube como Amazon Web Services (AWS) y Microsoft Azure se están adaptando a este nuevo paradigma: ofreciendo escala al lago de datos.
Los lagos de datos proporcionan un repositorio centralizado y escalable para todo tipo de datos, de múltiples fuentes diversas. Permiten a las organizaciones recopilar, preparar y utilizar de manera más eficiente sus grandes cantidades de datos para realizar análisis y, en última instancia, tomar decisiones comerciales informadas y basadas en hechos.
Centro Infra proporciona una descripción detallada de los lagos de datos, que permiten a las organizaciones almacenar, analizar y utilizar datos de una variedad de fuentes. Estos repositorios de datos están permitiendo a las organizaciones comprender, refinar y analizar petabytes (e incluso exabytes) de información que se genera constantemente.
Como describió el ex director ejecutivo de Google, Eric Schmidt, el panorama de los datos:
“Se crearon 5 exabytes de información desde los albores de la civilización hasta 2003, pero ahora esa cantidad de información se crea cada 2 días”.
Esta cita es del año 2013 – hace casi una década. Se estima que para 2025 el mundo generará 463 exabytes de datos en un solo día. Los datos que se generan están aumentando exponencialmente en lo que es un virtual tsunami de datos.
¿Qué es un lago de datos?
Un lago de datos es un repositorio centralizado, administrado y escalable que almacena datos no estructurados, semiestructurados y estructurados de múltiples fuentes diversas de una manera plana y no jerárquica. Este repositorio puede almacenar datos en su formato nativo y procesar cualquier variedad de ellos, ignorando los límites de tamaño.
Los lagos de datos están destinados a almacenar y administrar datos hasta que un usuario decida utilizarlos para análisis, análisis u otros casos de uso.
Para usar una analogía, un lago natural recolecta agua de diversas fuentes, como precipitaciones, arroyos, escorrentías y aguas subterráneas. De manera similar, los datos se incorporan a un lago de datos desde múltiples y diversas fuentes, que incluyen: aplicaciones comerciales, correo electrónico, imágenes, archivos de texto, redes sociales, secuencias de clics, dispositivos de Internet de las cosas (IoT), sensores y actuadores.
Diagrama del lago de datos
A continuación se muestra un diagrama de alto nivel que muestra i) diversas fuentes desde donde se incorporan los datos a un lago de datos y ii) casos de uso para los cuales se leen datos del lago de datos.
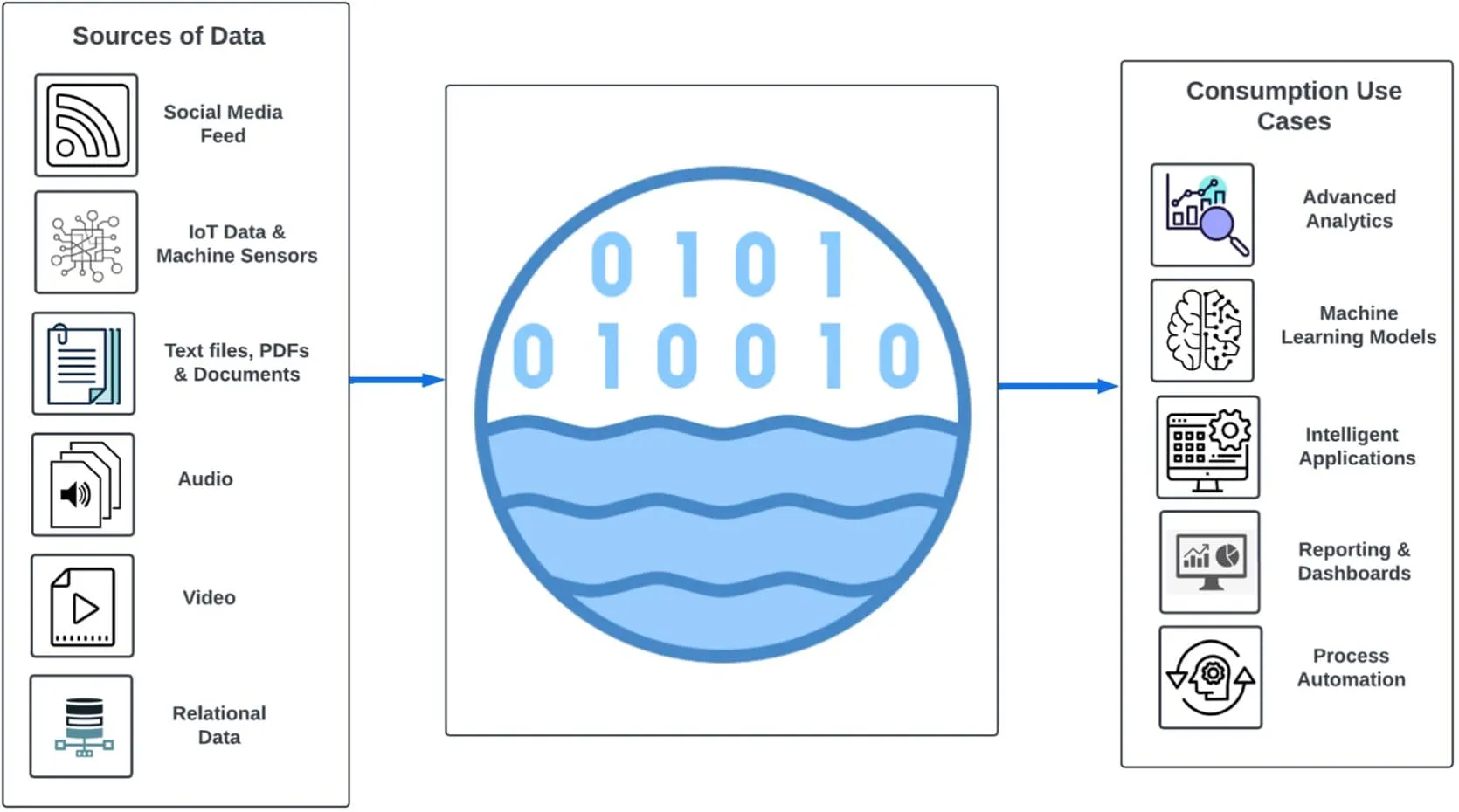
Haga clic aquí para ver una versión más grande de esta imagen.
Es importante destacar que estos datos se pueden incorporar desde cualquier entorno: local, en la nube o en el borde.
LEER MÁS: Migración local a la nube: un viaje a AWS y Azure
¿Por qué las empresas utilizan lagos de datos?
Las empresas utilizan lagos de datos en un intento de capturar la promesa de big data, que a menudo aún no se ha logrado en sus negocios. En las pequeñas, medianas y grandes empresas, los datos suelen estar aislados en Múltiples sistemas y departamentos, lo que dificulta a los usuarios encontrar y acceder a todos los datos que necesitan.
Además, el rendimiento de las consultas suele estar limitado por problemas de simultaneidad y escalabilidad. Si bien las arquitecturas complejas también resultan en tuberías de datos rotas, degradación del rendimiento, movimiento de datos propenso a errores, así como riesgos de seguridad y gobernanza.
Los lagos de datos están diseñados para gestionar grandes volúmenes de big data: piense en petabytes (1 millón de gigabytes) y exabytes (mil millones de gigabytes).
LEER MÁS: ¿Qué es Data Gravity? AWS y Azure extraen datos a la nube
Beneficios de un lago de datos
Fundamentalmente, las empresas pueden mover datos sin procesar, mediante procesamiento por lotes y flujos, a un lago de datos sin transformarlos. A su vez, los lagos de datos brindan los siguientes beneficios a las organizaciones:
- Costo total de propiedad (TCO): los lagos de datos proporcionan un medio económico para almacenar enormes cantidades de datos.
- Escalabilidad: los lagos de datos pueden escalarse fácilmente, lo cual se está volviendo cada vez más importante a medida que los datos se generan a un ritmo asombroso cada minuto, hora y día.
- Gestión de datos: los lagos de datos rompen los silos de datos combinando conjuntos de datos de diferentes sistemas en un único repositorio. A su vez, esto puede simplificar el proceso de encontrar datos relevantes entre organizaciones.
- Análisis: los lagos de datos aceleran el proceso de preparación de datos para usos analíticos, como paneles, visualizaciones, procesamiento de big data, análisis en tiempo real y aprendizaje automático (ML).
- Aprendizaje automático (ML) e Inteligencia artificial (IA): los lagos de datos actúan como un vehículo para análisis avanzados, como el entrenamiento de modelos de aprendizaje automático y herramientas de ciencia de datos, que permiten inteligencia artificial contra los datos almacenados en un lago de datos.
- Gobernanza: la gobernanza implica rastrear el linaje de datos, dado que los datos se ingieren de diferentes fuentes, así como hacer cumplir políticas de gobernanza, como la accesibilidad y la anonimización de los datos.
Ejemplo de caso de uso para un lago de datos: comercio electrónico
Las empresas de comercio electrónico generan enormes cantidades de datos, ya sean sobre productos o clientes, lo que convierte a estas empresas en un ejemplo relevante de cómo se pueden utilizar los lagos de datos.
Las actividades de adquisiciones, ventas, logística e inventario de una empresa de comercio electrónico producen una combinación de datos estructurados, semiestructurados y no estructurados. Al emplear un lago de datos, una empresa de comercio electrónico podría almacenar todos sus datos de estas fuentes disponibles, hasta que esté lista para analizar y utilizar los datos para:
- Predecir la demanda calculando en los patrones de compra de los consumidores en determinadas épocas del año, como días festivos o temporadas específicas.
- Planificar el surtido de productos y mezclar de forma óptima.
- Proporcionar recomendaciones de productos personalizados a los clientes.
- Identificar segmentos de clientes que estarían interesados en el lanzamiento de nuevos productos basados en comportamientos de compra anteriores.
- Describir posibles pasos para mejorar los tiempos de entrega y cumplimiento de pedidos.
¿Qué es un lago de datos, un almacén de datos y una base de datos?
Un lago de datos, un almacén de datos y una base de datos son depósitos de datos. Sin embargo, cada uno de estos repositorios de datos difiere de manera significativa, lo que hace que un lago de datos, un almacén de datos y una base de datos estén optimizados para diferentes usos.
Las diferencias clave entre un lago de datos, un almacén de datos y una base de datos son:
- Data Lake: almacena datos actuales e históricos de uno o más sistemas en su formato sin procesar (no estructurado, semiestructurado, estructurado), con un procesamiento mínimo o nulo. Un lago de datos está diseñado para almacenar cantidades masivas de datos y permite un fácil análisis de los datos.
- Almacén de datos: almacena datos actuales e históricos de uno o más sistemas en un esquema fijo y predefinido, es decir, cómo se organizan los datos. Esto, en combinación con un plan para procesar los datos, permite un fácil análisis de los datos pero hace que un almacén de datos sea menos flexible que una base de datos.
- Base de datos: almacena datos en vivo y en el tiempo real necesario para impulsar una aplicación, en tablas con filas y columnas. Una base de datos tiene un esquema flexible, es decir, cómo se organizan los datos. Dado que una base de datos contiene datos en un formato estandarizado y predecible, se la conoce como datos estructurados.
En general, un lago de datos y un almacén de datos se utilizan para análisis e informes (por ejemplo, informes de ventas mensuales), mientras que una base de datos está diseñada para operaciones y transacciones. Además, los datos del lago de datos y del almacén de datos se actualizan periódicamente, mientras que los datos de la base de datos están actualizados y detallados.
Al comparar un lago de datos directamente con un almacén de datos, las diferencias más significativas son su compatibilidad con tipos de datos y la flexibilidad de esquema. Los lagos de datos admiten todo tipo de datos, incluidos los no estructurados, mientras que los almacenes de datos almacenan principalmente datos estructurados. Además, los lagos de datos no tienen una definición de esquema, lo que les permite ingerir datos en una variedad de formatos, mientras que los almacenes de datos tienen un esquema fijo y predefinido.
Extraer, transformar, cargar (ETL) / Esquema en lectura
Cuando se leen datos de un lago de datos para un caso de uso determinado, se lleva a cabo un proceso de transformación de los datos, conocido como extracción, transformación, carga (ETL), lo que da como resultado la flexibilidad del esquema en lectura.
En lugar de requerir que los datos se ingresen en una estructura predefinida (como un almacén de datos), el proceso de lectura del esquema de un lago de datos crea una estructura a medida que se buscan los datos, lo que permite a los usuarios hacer preguntas nuevas y diferentes en cualquier momento, sin tener que volver a diseñar un esquema, como se requeriría en una base de datos relacional.
Más específicamente, este proceso crea un esquema en el momento de lectura, en lugar de en el momento de escritura, y no requiere conocimientos predefinidos sobre los datos que está procesando. A su vez, el esquema en lectura permite a diferentes usuarios ejecutar una variedad de consultas, independientemente de los cambios en el formato de los datos que se ingresan en el lago de datos.
Los tipos de datos determinan la forma en que se almacenan los datos.
Los sensores de las máquinas, los dispositivos de Internet de las cosas (IoT), las redes sociales, el correo electrónico, los mensajes de texto, las imágenes, los vídeos y los blogs se encuentran entre las diversas fuentes que actualmente generan cantidades increíbles de datos.
A menudo denominados grandes datos, la mayoría de estos datos no están estructurados o son semiestructurados y representan un gran tesoro de patrones, tendencias y conocimientos sin explotar que esperan ser transformados y aportados a programas de aprendizaje automático (ML) y algoritmos de análisis de datos.
Por ejemplo, las plataformas de redes sociales como Facebook, Twitter, Instagram y LinkedIn generan cantidades masivas de datos estructurados y no estructurados. La actividad relacionada con eventos y acciones como publicaciones, me gusta, recursos compartidos, seguidores y grupos representan datos estructurados, mientras que los videos, imágenes y archivos de audio cargados y compartidos representan datos no estructurados.
Los sistemas tradicionales de almacén de datos, debido a sus sistemas de almacenamiento internos orientados a esquemas, no pueden manejar datos no estructurados o semiestructurados. Como tal, los lagos de datos, que pueden almacenar datos estructurados, semiestructurados y no estructurados, son cada vez más importantes.
Soluciones de lago de datos basadas en la nube
Históricamente, las soluciones de lago de datos se creaban principalmente en las instalaciones. Sin embargo, las economías de escala y el almacenamiento de objetos económicos que ofrece la nube han dado como resultado que las soluciones de lagos de datos basados en la nube surjan como una opción rentable e inherentemente escalable.
Como tal, las implementaciones de lagos de datos existentes se están migrando a la nube y se están planificando nuevas implementaciones de lagos de datos en la nube, desde cero.
Los proveedores de servicios en la nube (CSP) ofrecen varios servicios integrados e interoperables que facilitan:
- Recopilar, ingerir, catalogar y gobernar datos.
- Crear, proteger y gestionar un lago de datos.
- Analizar y consultar datos o utilizarlos para cualquier caso de uso de consumo determinado.
Normalmente, los CSP proporcionan soluciones de lago de datos que se incluyen como servicios de pago por uso, que ofrecen:
- Acceso bajo demanda a usuarios empresariales, científicos de datos o analistas de datos
- Interoperabilidad con herramientas y aplicaciones analíticas a través de puntos finales, interfaces e interfaces de programación de aplicaciones (API)
- Salvaguardias de seguridad y controles de acceso para regular cualquier acceso por parte de usuarios finales, servicios, aplicaciones o API.
LEER MÁS: Los 10 principales proveedores de servicios en la nube a nivel mundial
Como se analiza a continuación, los proveedores de servicios en la nube (CSP), incluidos Amazon Web Services (AWS), Microsoft Azure y Google Cloud, ofrecen almacenamiento de objetos, que es uno de los componentes fundamentales de un lago de datos.
Servicios web de Amazon (AWS) – Lago de datos
Amazon Web Services (AWS) ofrece un [conjunto de servicios] integrado (https://aws.amazon.com/solutions/implementations/data-lake-solution/) para que los clientes implementen una solución de análisis y almacenamiento de lagos de datos.
Para el almacenamiento de objetos, AWS utiliza Amazon S3 (Servicio de almacenamiento simple). S3 es un servicio de almacenamiento de objetos sólidos y escalables que es la base para alojar lagos de datos en AWS.
Otra solución de lago de datos que se utiliza ampliamente es AWS Glue, que es un servicio de integración de datos que ejecuta trabajos de extracción, transformación y carga (ETL) para cargar datos en un lago de datos. Por ejemplo, estos trabajos de ETL se pueden ejecutar tan pronto como haya nuevos datos disponibles en Amazon S3.
AWS Glue ofrece las siguientes capacidades clave al momento de crear un lago de datos:
- Capacidad para crear rastreadores que pueden descubrir fuentes de datos clave conectándose a almacenes de datos compatibles, como Amazon Relational Database Service (RDS), instancias de bases de datos en Amazon Elastic Compute Cloud (Amazon EC2), Amazon DynamoDB y otros objetos de S3.
- Almacena metadatos sobre los datos que se incorporan a un lago de datos (a través del catálogo de datos de AWS Glue). Permite que los usuarios finales descubran esos datos fácilmente
- Permite a los usuarios finales crear trabajos de extracción, transformación y carga (ETL) para limpiar y transformar datos.
Formación del lago AWS
AWS Lake Formation es un servicio administrado que permite la automatización de todo el proceso de creación de un lago de datos. El servicio organiza el descubrimiento, la ingesta, la limpieza, la depuración y la catalogación de datos. Al utilizar AWS Lake Formation, una organización puede reducir el tiempo que lleva configurar un lago de datos operativo.
Amazon Athena, Amazon EMR y Amazon SageMaker
AWS proporciona los siguientes servicios cuando los datos ya se han cargado en un lago de datos:
- Amazon Athena y Amazon EMR son servicios para consulta y análisis de datos.
- Amazon SageMaker, una plataforma de aprendizaje automático (ML) en la nube, simplifica la creación e implementación de modelos de aprendizaje automático con entradas de conjuntos de datos almacenados en lagos de datos de AWS.
LEER MÁS: regiones y zonas de disponibilidad de Amazon Web Services (AWS)
Microsoft Azure: lago de datos
Microsoft Azure tiene varios servicios que permiten a las organizaciones configurar rápidamente lagos de datos y permitir a los usuarios finales, como científicos de datos y analistas de negocios, acceder y analizar los datos. De manera única, Azure proporciona almacenamiento multimodal, lo que significa que sus servicios de lago de datos admiten ambos:
- Almacenamiento de objetos, al que Microsoft Azure se refiere como almacenamiento blob
- Archivos compartidos, conocidos como Azure Files, a los que se puede acceder a través del protocolo Server Message Block (SMB), el protocolo Network File System (NFS) y la API REST de Azure Files.
Azure Data Lake Storage Gen2 es el conjunto de capacidades de Microsoft que hacen de Azure Storage la base para crear lagos de datos empresariales en Azure. Específicamente, estas capacidades proporcionan semántica del sistema de archivos, seguridad a nivel de archivos y escala.
En general, Azure Data Lake Storage Gen2 está diseñado para almacenar cantidades masivas de datos, es decir, varios petabytes de información, manteniendo al mismo tiempo cientos de gigabits por segundo (Gbps) de rendimiento.
Además, Microsoft Azure proporciona capacidades analíticas de lagos de datos a través de los dos servicios administrados siguientes:
- Azure Synapse Analytics: servicio de integración de datos, almacenamiento de datos empresariales y análisis de big data
- Azure Databricks: Servicio de análisis de big data basado en Apache Spark diseñado para analistas de datos, ingenieros de datos, científicos de datos e ingenieros de aprendizaje automático.
LEER MÁS: regiones y zonas de disponibilidad de Microsoft Azure
Google Cloud: lago de datos
Google Cloud Platform (GCP) proporciona varios servicios para crear lagos de datos rentables, escalables y confiables. Por ejemplo, Google Cloud Storage es un servicio administrado para almacenar y acceder a cualquier cantidad de datos no estructurados.
En general, los servicios de lago de datos de Google Cloud brindan las siguientes capacidades:
- Transfiera datos de forma segura y rápida desde diversas fuentes a un lago de datos
- Facilitar el descubrimiento fácil de datos por parte de los usuarios finales a través de la catalogación de datos.
- Garantizar la interoperabilidad con motores y servicios analíticos nativos, de terceros y de código abierto.
Google Cloud proporciona varios métodos para transferir datos a un lago de datos, que incluyen:
- Interconexión dedicada: conexiones físicas directas entre la red local de una organización y la red de Google en una instalación de colocación
- Interconexión de socios: conectividad entre la red local de una organización y su red Nube privada virtual (VPC) a través de un proveedor de servicios de red. Estas conexiones se utilizan comúnmente cuando el centro de datos de una organización se encuentra en una ubicación física que no puede llegar a una instalación de instalación de interconexión dedicada.
- Cloud Data Fusion: servicio de integración de datos totalmente administrado que ayuda a los usuarios a crear y administrar canales de datos de extracción, transformación y carga (ETL).
- Dispositivo de transferencia: dispositivo de almacenamiento con 7 terabytes a 300 terabytes de capacidad que permite a los usuarios transferir de manera básica y enviar sus datos a Google para cargarlos.
- Pub/Sub: servicio utilizado para análisis de streaming y canalizaciones de integración de datos para ingerir y distribuir datos.
Por último, Google Cloud proporciona herramientas como Dataproc, Dataflow y BigQuery para realizar consultas, análisis y modelos de aprendizaje automático tanto en modo por lotes como en modo continuo.
LEER MÁS: regiones y zonas de disponibilidad de Google Cloud



