
El aprovisionamiento, el mantenimiento y la operación de servidores y tiempos de ejecución es una tarea que requiere muchos recursos y que evita que los equipos organizacionales se centren únicamente en la innovación empresarial y las funciones principales. En consecuencia, las organizaciones están cambiando hacia una arquitectura de computación en la nube sin servidores, lo que implica transferir la implementación de aplicaciones y el lado del servidor de TI a proveedores de servicios externos.
Sin servidor es la idea de que las organizaciones pueden ejecutar aplicaciones basadas en servidor sin tener que administrar un servidor. El modelo sin servidor requiere que las aplicaciones se implementen como un conjunto de componentes autónomos que se construyen “como un servicio” y se pueden invocar bajo demanda, incurriendo en costos solo cuando están en uso.
Centro Infra explica la computación sin servidor, su arquitectura y en qué se diferencia de otros modelos de computación en la nube. También profundizamos en las ventajas, desventajas y casos de uso comunes de la tecnología sin servidor. Finalmente, destacamos los principales servicios sin servidor de proveedores de servicios en la nube (CSP) como Amazon Web Services (AWS), Microsoft Azure y Google Cloud.
¿Qué es Serverless?
Tradicionalmente, las organizaciones respaldaban la infraestructura necesaria para ejecutar sus aplicaciones y cargas de trabajo en sus instalaciones. Tecnologías como virtualización de servidores les permitieron crear varios servidores virtuales, cada uno con su propio sistema operativo (OS) y tiempo de ejecución, en un único servidor físico para una mejor utilización de los recursos. A continuación, surgieron modelos de computación en la nube como Infraestructura como servicio (IaaS) y Plataforma como servicio (PaaS), lo que permitió a las organizaciones descargar sus necesidades de infraestructura a un proveedor de servicios en la nube (CSP) para facilitar la gestión, mayor elasticidad y rentabilidad.
Sin embargo, las organizaciones, en particular los desarrolladores, siguen siendo responsables de algunas configuraciones, como configurar el entorno de implementación, administrar las licencias de software y activar instancias virtuales según sea necesario.
Definición de informática sin servidor
La informática sin servidor, o “sin servidor” para abreviar, oculta toda la arquitectura backend a los desarrolladores. Abstrae la aplicación como funciones autónomas alojadas, administradas y mantenidas por un proveedor externo. Luego, estas funciones se consumen como un servicio de utilidad y se ejecutan solo cuando se invocan. Los costos también se generan en función del número de veces que se ejecuta cada función.
“Sin servidor” es, de hecho, un calificativo que se puede aplicar a cualquier oferta de software u servicio, que requiere que se consuma como un servicio público e incurra en costos solo cuando se usa. Por ejemplo, el software que requiere un servidor para alojar un sitio web, como el servidor HTTP Apache, no es sin servidor ya que no cumple con el criterio de “consumido como un servicio de utilidad”. De manera similar, el software que está disponible “como servicio” pero requiere una tarifa de suscripción básica fija independientemente de su uso, como Salesforce, tampoco es sin servidor ya que no cumple con el criterio de “incurre en costos solo cuando se usa”.
Con la tecnología sin servidor, los desarrolladores son los únicos responsables de crear la lógica empresarial de las aplicaciones, no la pila de software y hardware subyacente. Las aplicaciones sin servidor se ejecutan solo en respuesta a eventos y tráfico específicos, y pueden escalar hacia arriba y hacia abajo automáticamente, incluso hasta cero, sin pronósticos ni configuraciones previas. Las arquitecturas sin servidor prometen a los desarrolladores la capacidad de iterar lo más rápido posible mientras mantienen las garantías de latencia, disponibilidad, seguridad y rendimiento críticas para el negocio con un mínimo esfuerzo por parte de los desarrolladores.
¿Cómo funciona la tecnología sin servidor?
La informática sin servidor no significa que ya no se requieran servidores o ingenieros de operaciones para alojar y ejecutar el código. Simplemente se refiere a la idea de que los consumidores de informática sin servidor ya no son responsables del aprovisionamiento, el mantenimiento, la actualización, el escalado y la planificación de la capacidad del servidor. En cambio, todas estas tareas y capacidades se abstraen de los desarrolladores y de los equipos internos de TI/operaciones y se delegan a la plataforma sin servidor y al proveedor de servicios. Dicho de otra manera, “less” en “serverless” indica invisibilidad en el contexto de uso, no ausencia.
Las aplicaciones sin servidor se pueden crear utilizando una colección de servicios o funciones administrados a los que se puede llamar a través de interfaces de programación de aplicaciones (API). Esto se conoce como modelo backend como servicio (BaaS). Por ejemplo, los desarrolladores pueden utilizar un servicio para autenticación y otro para almacenamiento y recuperación de datos. Alternativamente, los desarrolladores pueden escribir una lógica personalizada del lado del servidor que se ejecute en contenedores totalmente administrados por un proveedor de servicios en la nube (CSP). Este modelo se conoce como función como servicio (FaaS) y se hace referencia más comúnmente cuando se habla de tecnología sin servidor.
En cualquier caso, los desarrolladores no son responsables de configurar o administrar la infraestructura para ejecutar estos servicios. Estos servicios no dependen del acceso directo a un servidor para funcionar. En cambio, el proveedor de servicios en la nube activa un servidor a corto plazo cada vez que es necesario ejecutar la aplicación. El servidor finaliza tan pronto como se completan las tareas. A menos que se invoquen, las aplicaciones sin servidor no reservan ni consumen ningún recurso, lo que permite una facturación estrictamente de “pago por uso”.
Arquitectura sin servidor
La arquitectura sin servidor se basa principalmente en eventos. Aprovecha implementaciones sin servidor (sin configuraciones de infraestructura manuales) de componentes individuales y autónomos que se suministran “como un servicio”. Luego, los servicios se ejecutan y se comunican entre sí en respuesta a desencadenadores de eventos específicos. Los desarrolladores pueden utilizar varias API y servicios web potentes y de un solo propósito para crear rápidamente aplicaciones eficientes, escalables y poco acopladas.
Una arquitectura sin servidor para una aplicación puede tener varias capas, cada una de las cuales utiliza servicios existentes de proveedores de nube como Amazon Web Services (AWS) y Microsoft Azure para implementar sus componentes arquitectónicos. Los proveedores de servicios en la nube ofrecen catálogos completos de servicios sin servidor para crear API, flujos de trabajo, colas, bases de datos y más.
Ejemplo de arquitectura sin servidor
Como ejemplo, considere una aplicación web simple sin servidor para solicitar un viaje, a través de una aplicación de viajes compartidos bajo demanda como Uber, creada con servicios sin servidor de AWS. Puede utilizar Amazon API Gateway para enrutar las solicitudes de los usuarios (activadores de eventos) a funciones relevantes de AWS Lambda. La función Lambda ejecuta operaciones necesarias, como seleccionar un viaje disponible de una tabla de Amazon DynamoDB y devolver los resultados al usuario.
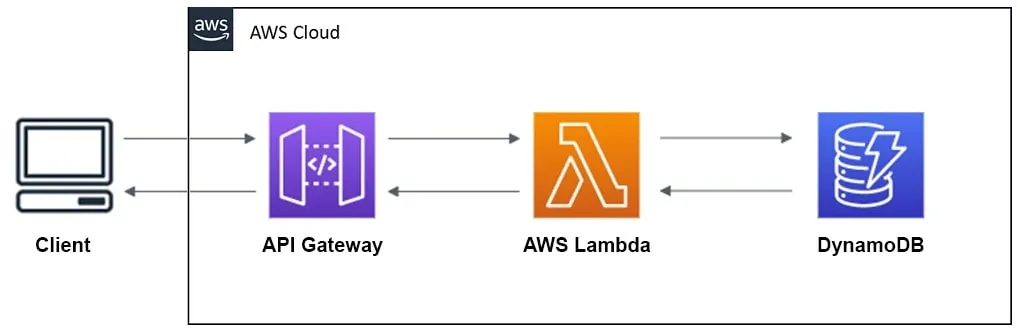
Fuente: Servicios web de Amazon (AWS).
Básicamente, la función Lambda, tras su invocación, se ejecutará en un contenedor sin estado que finalizará una vez que se ejecute la función.
Ventajas y desventajas de Serverless
Sin servidor se trata de descargar el trabajo pesado indiferenciado a otros, reducir ciertas preocupaciones operativas, avanzar hacia la informática basada en eventos y brindar a las organizaciones espacio para concentrarse en lo que es importante: los objetivos centrales de su negocio o proyecto.
¿Cuáles son las ventajas de Serverless?
Las ventajas de la tecnología sin servidor son el enfoque organizacional, la escalabilidad, la alta disponibilidad, el pago por uso y la complejidad reducida.
- Enfoque organizacional: la arquitectura sin servidor permite a los desarrolladores centrarse en el diseño de software y la lógica empresarial en lugar de en la infraestructura, las licencias de software y la planificación de capacidad. Como resultado, las organizaciones disfrutan de una innovación acelerada y un tiempo de comercialización más rápido.
- Escalabilidad: los sistemas sin servidor aumentan y disminuyen automáticamente en cuestión de segundos. De hecho, permiten el escalado granular de funciones particulares que enfrentan una gran demanda. Los desarrolladores no tienen que planificar picos de demanda repentinos e impredecibles, excepto cuando interactúan con otros componentes o sistemas que no son sin servidor.
- Alta disponibilidad: la arquitectura sin servidor ofrece alta disponibilidad como característica estándar. Las organizaciones pueden implementar sus aplicaciones sin servidor en diferentes zonas de disponibilidad en regiones geográficas separadas de la nube sin costos incrementales. Permite a las organizaciones integrar servicios de recuperación ante desastres y garantizar una alta disponibilidad y rendimiento según el acuerdo de nivel de servicio (SLA) del proveedor de la nube.
- Pago por uso: la tecnología sin servidor es más rentable porque los consumidores pagan solo por lo que usan. Las aplicaciones y sistemas sin servidor pueden reducirse rápidamente a actividad cero, lo que significa que no se desperdician recursos durante los tiempos de inactividad. A los consumidores se les cobra según la cantidad de veces que se invoca una función o se realiza una tarea en lugar de las horas de instancia.
- Complejidad reducida: la tecnología sin servidor elimina el código indiferenciado, como el necesario para orquestar flotas de servidores o enrutar solicitudes y eventos entre componentes, lo que forma una parte sorprendentemente grande de las bases de código modernas. A su vez, los equipos de desarrollo tienen menos código que escribir y mantener por aplicación.
¿Cuáles son las desventajas de Serverless?
Las desventajas de la tecnología sin servidor son los límites de tiempo de ejecución, los arranques en frío, la dependencia del proveedor y la pérdida de control.
- Límites de tiempo de ejecución: una debilidad clave de la tecnología sin servidor es la cantidad limitada de tiempo que una carga de trabajo particular puede ejecutarse antes de finalizar. Por ejemplo, las funciones de AWS Lambda solo pueden ejecutarse hasta 15 minutos por ejecución. Existen soluciones alternativas, pero puede resultar más rentable ejecutar aplicaciones de larga duración en servidores dedicados que sin servidor.
- Arranques en frío: la tecnología sin servidor puede escalar a cero durante el tiempo de inactividad, lo que genera recortes de costos. Sin embargo, si una función se ejecuta después de que sus recursos se hayan agotado por completo, el entorno de ejecución deberá iniciarse nuevamente en la siguiente llamada, lo que lleva tiempo. Como resultado, la tecnología sin servidor ofrece diferentes características de rendimiento para funciones ejecutadas con frecuencia o recientemente frente a funciones inactivas. Nuevamente, existen soluciones para evitar arranques en frío, como mantener los recursos en espera o iniciar solicitudes ficticias. Sin embargo, estas soluciones pueden desafiar la característica de “pago por uso” de las tecnologías sin servidor.
- ** Dependencia del proveedor: ** otra desventaja de la informática sin servidor es que el código de función está directamente vinculado a la plataforma de software en la que se ejecuta. Con el tiempo, esto podría limitar la portabilidad a medida que la arquitectura de la aplicación se acople fuertemente a la plataforma que se utiliza. Las aplicaciones y cargas de trabajo que deben seguir siendo independientes del proveedor deben diseñarse teniendo en cuenta las implicaciones de la dependencia del proveedor y los riesgos inherentes de los servicios de terceros, como la soberanía de los datos, la cartera de servicios, el costo y el soporte.
- Pérdida de control: las eficiencias obtenidas al descargar el “trabajo pesado” a los CSP se obtienen a expensas de la visibilidad y el control. Los desarrolladores pierden la capacidad de personalizar el sistema operativo (SO) o modificar la instancia subyacente. Además, cuando todo el proceso es efímero, diagnosticar problemas y depurar el código se vuelve excepcionalmente complejo. Los diferentes proveedores de servicios ofrecen distintos niveles de personalización y flexibilidad.
¿Cuándo se debe utilizar Serverless?
Según las características y ventajas del enfoque sin servidor, es más adecuado para cargas de tráfico impredecibles y organizaciones que necesitan innovar y moverse rápidamente. Las funciones sin servidor son versátiles porque se pueden utilizar para crear backends para aplicaciones CRUD (Crear, Leer, Actualizar, Eliminar), comercio electrónico, sistemas administrativos, aplicaciones web complejas y todo tipo de software móvil y de escritorio. Las funciones sin servidor son sin estado de forma predeterminada, lo que las hace perfectas para implementar cualquier lógica que se beneficie del procesamiento paralelo.
¿Cuándo no se debe utilizar Serverless?
Para adoptar la tecnología sin servidor, es necesario dividir la aplicación en cargas de trabajo más pequeñas. Teniendo en cuenta los inconvenientes y las preocupaciones que rodean la tecnología sin servidor, no funciona mejor para tareas que requieren un uso intensivo de computación o que tienen un tiempo de ejecución prolongado, que no se puede dividir en múltiples ciclos de computación.
Casos de uso sin servidor
Las tecnologías y arquitecturas sin servidor se pueden utilizar para construir sistemas completos, crear componentes aislados o implementar tareas granulares específicas. El alcance para el uso del diseño sin servidor es amplio: puede usarse para diseñar sistemas que impulsen aplicaciones web y móviles para decenas de miles de usuarios, así como para construir sistemas que resuelvan problemas diminutos y muy específicos. De hecho, a menudo se utiliza para tareas de backend que impulsan aplicaciones o sitios web complejos.
Ejemplos de casos de uso sin servidor
Ejemplos de casos de uso sin servidor incluyen computación backend, análisis en tiempo real, Internet de las cosas (IoT) y tareas periódicas en la nube.
1) Computación de backend
La escala casi infinita y la arquitectura basada en eventos de la tecnología sin servidor permiten una potencia informática precisa para cualquier escala, lo que la hace adecuada para tareas de backend como el procesamiento de datos en masa. Con la tecnología sin servidor, las organizaciones pueden dividir y paralelizar el trabajo y alimentarlo instantáneamente con tantas funciones sin servidor como sean necesarias. Por ejemplo, el tiempo que lleva procesar un minuto de vídeo de alta resolución para su transmisión es también el tiempo que lleva procesar una película de 90 minutos, ya que la película se puede dividir en fragmentos más pequeños y procesar simultáneamente. Este es un ejemplo de cómo Netflix utiliza la tecnología sin servidor.
2) Análisis en tiempo real
Las funciones sin servidor son adecuadas para aplicaciones que generan una gran cantidad de datos que deben analizarse, agregarse y almacenarse. Las funciones sin servidor totalmente administradas pueden escalar automáticamente según el volumen de datos que ingresan.
3) Internet de las cosas (IoT)
Serverless es una excelente opción para las aplicaciones de Internet de las cosas (IoT) que utilizan Internet para leer y escribir datos. Un backend de aplicación sin servidor elimina gran parte de la administración de la infraestructura, ofrece facturación granular y predecible y se escala bien para satisfacer demandas desiguales. Es por eso que servicios como Alexa, la tecnología de asistente virtual de Amazon, e iRobot, que diseña y construye robots de consumo como aspiradoras, utilizan la tecnología sin servidor.
LEER MÁS: Dispositivos de Internet de las cosas (IoT): ¿Qué será inteligente en 2023?
4) Tareas periódicas en la nube
Las funciones sin servidor se pueden utilizar para automatizar tareas en la nube que no necesitan un servidor funcionando constantemente pero que deben realizarse de forma recurrente, como realizar copias de seguridad periódicas de bases de datos y actualizaciones de software automatizadas.
Servicios sin servidor
Existen numerosos servicios y plataformas sin servidor que las organizaciones pueden elegir para utilizar el sistema sin servidor. Dado que existen bastantes enfoques para implementar la tecnología sin servidor, todos los proveedores tienen servicios distintos. Las organizaciones deben considerar toda la cartera de servicios que ofrece un proveedor y su acuerdo de nivel de servicio (SLA) para garantizar que puedan adoptar y beneficiarse con éxito de la arquitectura sin servidor.
A continuación se muestran algunos de los servicios sin servidor de los principales proveedores de servicios en la nube (CSP):
Servicios web de Amazon (AWS)
Amazon Web Services (AWS) ofrece una cartera completa de servicios para habilitar y respaldar arquitecturas sin servidor. Incluyen:
- AWS Lambda: un servicio informático sin servidor para ejecutar código
- Amazon S3 (Servicio de almacenamiento simple): un servicio de almacenamiento de objetos sin servidor, totalmente elástico y de alta disponibilidad.
- Amazon DynamoDB: un servicio de base de datos NoSQL sin servidor y totalmente administrado
- Amazon Aurora Serverless: configuración de escalado automático bajo demanda para Amazon Aurora: servicio de base de datos relacional compatible con MySQL y PostgreSQL de Amazon
Microsoft Azure
Los servicios sin servidor de Microsoft Azure incluyen:
- Azure Functions: una plataforma informática sin servidor para ejecutar código
- Azure Cosmos DB: un servicio de base de datos relacional y NoSQL totalmente administrado con una oferta sin servidor
- Azure Bot Service: un servicio de bot inteligente sin servidor
- Azure Event Hubs: un servicio de ingesta de eventos y datos totalmente administrado y altamente escalable
Nube de Google
Los servicios sin servidor de Google Cloud incluyen:
- Funciones de Google Cloud: computación sin servidor para ejecutar código
- Google App Engine: una plataforma sin servidor para alojar aplicaciones web y móviles
- Dataflow: un servicio sin servidor totalmente administrado para procesamiento de datos por secuencias y por lotes



